As with any software that I run, I would sure love for it to just stay up and running all the time. It doesn’t always happen.
This is a post about my own personal quest to keep my server up and running for a prolonged period of time without it going down for some odd reason.
My current monitoring baseline:
- Pingdom (free tier) Health checks every 5 mins
- Load Balancer from AWS with Listeners on port 80 and 443
- No AWS CloudWatch metrics or monitoring
My self hosted website and monitoring has evolved over the years in the following ways:
Stage 1: BeagleBoard
I decided to go this route for a number of reasons, but primarily because we were working with them at work back in 2013. I had become pretty familiar with our Beagleboard setup, and we seemed to be having great success hosting a small web application from it, so why not my personal website?
Big mistake – the board was plagued with memory issues, at the time it was running MySQL, WordPress, and Apache. The website went down so often it was only then when I decided to stand up monitoring and alerting based on when a simple ping failed.
Stage 2: AWS Server
Running your own server isn’t that great when you are constantly having to reboot it due to memory issues, and inconsistent performance when site attacks happened. So, I decided to jump ship and move everything up into the cloud midway through 2014. The instance types are now known as a t2 or m4 but when I first started I was just barely using a t2.nano and it was working great.
Towards the end of 2014 I started seeing new issues with the machine I was running and bumped the network and CPU up to a ‘t2.micro’ size, but the machine was great for my needs and the server load.
Stage 3: Hardening
I needed better monitoring, as the botnets from all over the world had somehow picked me as a great target for a classic XMLRPC WordPress exploit. Luckily I had already mitigated that type of attack within my own setup, but the bots just kept coming. So I set real monitors up thanks to Pingdom, and also set up CloudFlare as a way to mitigate bot networks.
My mistake was assuming that a third party like CloudFlare actually was able to spot bot-like attacks, so yet again I had to find another pieces of software that could assist my in mitigating attacks even after they slipped through the cracks. This time, I installed Fail2ban and at any given point I could check the status of fail2ban and get 10 currently banned IPs.
There are a number of failure points at this stage of my setup:
- Legitimate attack on my website to take it down – These are probably the most annoying, but spam bots and other types of floods my server simply cannot handle. It isn’t going to use autoscaling to dynamically handle the load, it is just going to crash. Whether that is MySQL running out of memory, php crashing, or some other issue, it just needs to be kicked back online.
- Load Balancer health check for my server – This was absolutely the biggest pain I have ever experienced, and I don’t know why. I swear I must have been on faulty hardware, but my AWS Load Balancer would randomly act up and say my website was unavailable. When this happens, your machine is taken out of rotation, and you’ve got no more website online! I fought this load balancer for years and never could figure it out.
That takes us from around 2015 to mid 2017. Filled with lots of attacks, instability due to internal errors, and a bunch of learning around it.
Stage 4: Stabilization
This is actually where I sit right now, as I finally switched over to the Application Load Balancers from AWS. What do you know? the first full month I switched my uptime for my website went to 100%. In my opinion it is worth every penny to switch over. In more recent times the bot-net style attacks have subsided however that is only temporary I imagine.
I bumped up the server size as well to give me a bit of a buffer, and besides my own doings and faults over the past couple of months there have been no hardware/software related outages, which is awesome.
Summary
In reality these lessons are only learned when you have to face them yourself. Monitoring, alerting, and proper sizing of your servers can go a long way. On top of that, adding application level protections can give you a much better chance at keeping your website 100% online.
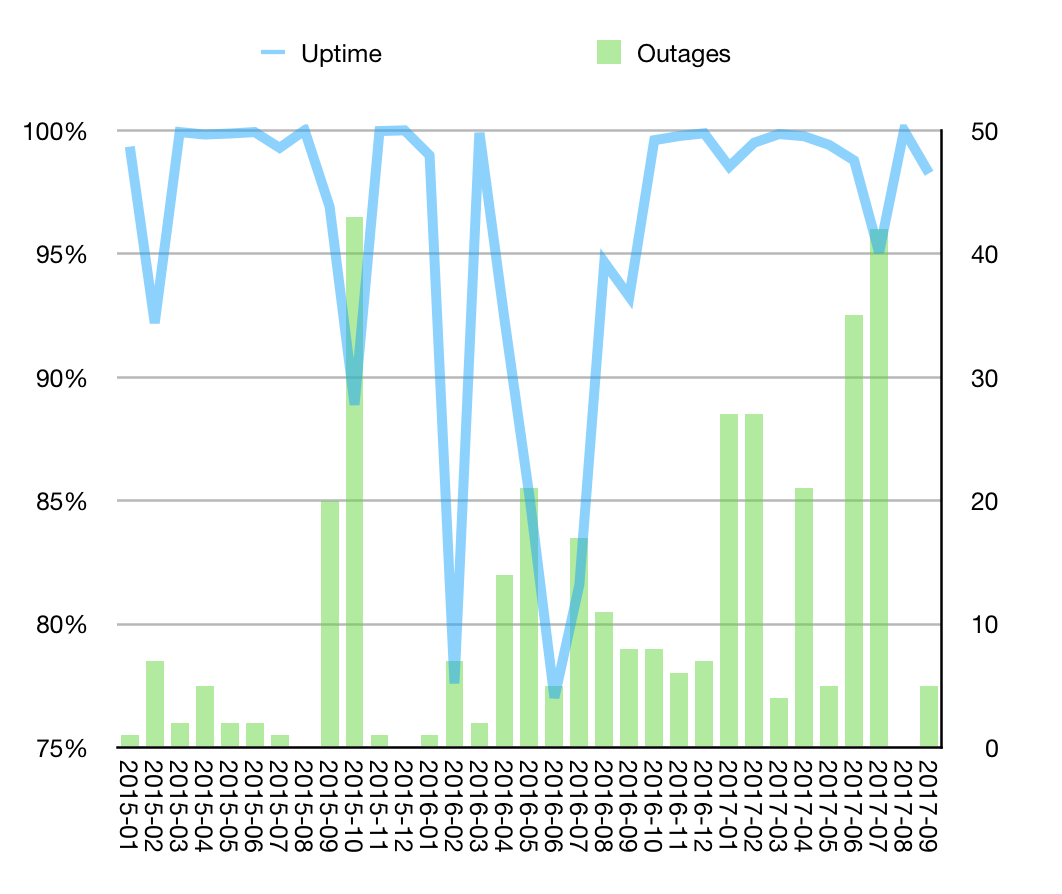
I have been pretty happy with both the monitoring/alerting functionalities I have chosen, as well as the continued stability improvements for just committing and paying a bit extra for some higher quality services.
As I look towards the future, I think about how I could host a static website on S3 for cheap, as well as using other serverless architectures like AWS Lambda or AWS ECS. Both have very different use cases but still help eliminate pain points of running your own hardware and infrastructure.
The quest for 100% uptime will always be something to work towards, but for now I think having a 96% average uptime across the years I have been tracking this statistic, with on average 10 outages (and around 1 full day) of downtime I don’t think is really that bad. Pretty sure back when I was in school a 96% was an A+…